Ping: o que é, como funciona, como ler a saída e usar no monitoramento de redes
O ping é provavelmente o primeiro comando que um administrador de redes executa ao investigar um problema de conectividade. Em 4 linhas de saída, ele entrega informações sobre disponibilidade, latência, perda de pacotes e número de saltos até o destino. É a ferramenta de diagnóstico mais simples e mais usada em infraestrutura de TI — e é exatamente por isso que entendê-la profundamente importa mais do que parece.
O ping funciona enviando pacotes ICMP Echo Request a um endereço IP ou hostname e aguardando o retorno ICMP Echo Reply. O tempo entre o envio e o recebimento da resposta é o RTT (Round Trip Time), ou latência de ida e volta. Se o destino não responde, o ping retorna Request timed out — o que pode indicar falha de conectividade, mas também pode simplesmente indicar que o host está bloqueando pacotes ICMP.
Para equipes de NOC e administradores de redes, o ping é o ponto de partida do diagnóstico. Este artigo cobre o que cada campo da saída significa, como interpretar os resultados corretamente e quais são os limites do ping no monitoramento corporativo contínuo.
Como o ping funciona tecnicamente
O ping opera no protocolo ICMP (Internet Control Message Protocol), definido na RFC 792. Ele envia pacotes Echo Request com um identificador e número de sequência para o destino. O host de destino, ao receber o pacote, responde com um Echo Reply contendo os mesmos dados. O tempo decorrido entre envio e resposta é o RTT.
Por padrão, o ping no Windows envia 4 pacotes de 32 bytes e para. No Linux e macOS, o ping continua indefinidamente até ser interrompido com Ctrl+C. Para testes contínuos no Windows, o parâmetro ping -t endereço mantém o envio ativo.
O protocolo ICMP opera na camada de rede (Layer 3 do modelo OSI), abaixo do TCP e UDP. Isso significa que o ping testa a conectividade na camada IP — não valida se uma aplicação está funcional, nem se uma porta TCP específica está aberta.
Lendo a saída do ping: o que cada campo significa
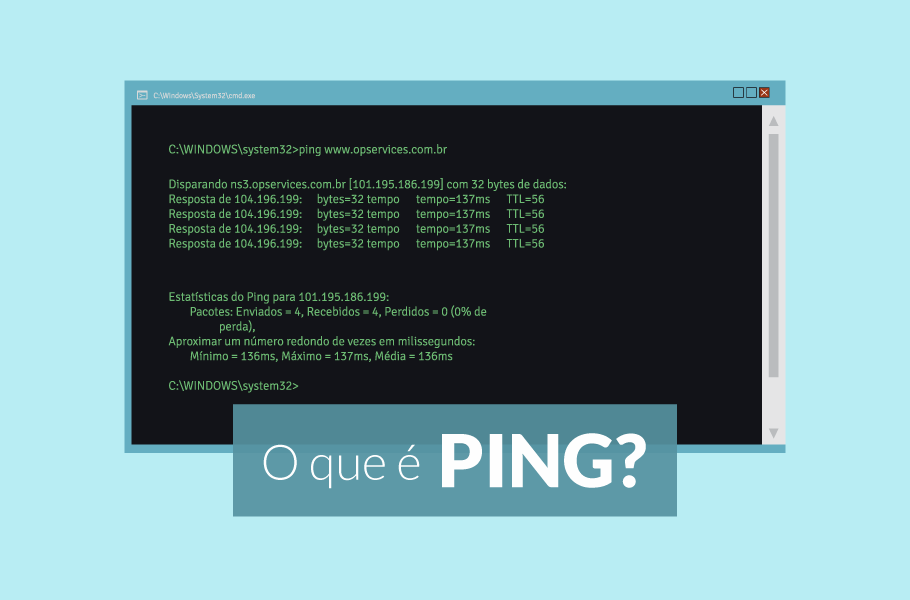
A saída de um ping típico no Windows tem esta estrutura:
Resposta de 8.8.8.8: bytes=32 tempo=12ms TTL=118
Cada campo tem significado operacional relevante.
RTT (tempo de resposta em ms)
O RTT é a métrica central do ping. Indica quantos milissegundos levaram para o pacote ir ao destino e voltar. Valores esperados dependem da distância física e da infraestrutura: pings para o gateway local tipicamente respondem em 1ms ou menos; pings para servidores em outro país podem variar de 100ms a 300ms.
Para latência em ambientes corporativos, valores acima de 100ms já podem indicar degradação perceptível em aplicações sensíveis como VoIP e videoconferência. A saída final do ping fornece os valores mínimo, médio e máximo do RTT — a diferença entre mínimo e máximo é o jitter, indicador de instabilidade na conexão.
TTL (Time to Live)
O TTL é o campo mais subestimado na saída do ping. Ele representa o número máximo de saltos (hops) que um pacote pode percorrer antes de ser descartado — cada roteador que o pacote atravessa decrementa o TTL em 1. Quando chega a zero, o pacote é descartado e o remetente recebe um ICMP Time Exceeded.
O TTL na saída do ping é o valor restante após a viagem. Sistemas operacionais definem valores iniciais distintos: Windows inicia com 128, Linux com 64 e equipamentos Cisco com 255. Assim, ao receber um TTL de 118 de um servidor Windows, é possível inferir que o pacote atravessou aproximadamente 10 roteadores (128 - 118 = 10). Essa informação é útil para estimar a topologia entre dois pontos sem precisar executar um traceroute completo.
Perda de pacotes
O resumo final do ping exibe os pacotes enviados, recebidos e a percentagem de perda. Em uma rede estável, a perda deve ser zero. Qualquer perda de pacotes acima de 1% em links corporativos é sinal de problema — congestionamento, hardware degradado, link saturado ou interferência em redes sem fio. Em ambientes VoIP, perda acima de 5% já torna a comunicação inaceitável.
Quando o ping falha mas o host está online
Um erro frequente de diagnóstico é interpretar “Request timed out” como prova de que o host está inacessível. Administradores de segurança frequentemente bloqueiam respostas ICMP em firewalls e sistemas operacionais para dificultar enumeração de hosts e ataques como ping flood. Nesse caso, o host está perfeitamente funcional — simplesmente não responde ao ICMP.
Para validar se um host está online apesar de não responder ao ping, use ferramentas que testam camadas superiores: Test-NetConnection -Port 443 -ComputerName endereço no PowerShell (Windows) ou nc -zv endereço 443 no Linux testam se uma porta TCP específica está acessível, independentemente da política ICMP.
Isso tem impacto direto no monitoramento de servidores: configurar alertas baseados apenas em ping pode gerar falsos positivos em servidores com ICMP bloqueado. Plataformas de monitoramento maduras combinam ping ICMP com verificação de porta TCP e verificação de serviço para eliminar falsos positivos.
Ping no monitoramento contínuo de infraestrutura
O ping executado manualmente é útil para diagnóstico pontual. No contexto de operações de TI, o que importa é o monitoramento contínuo automatizado: verificar periodicamente a disponibilidade e a latência de cada dispositivo da infraestrutura e alertar quando os thresholds são violados.
Plataformas como o OpMon (da OpServices) e outras ferramentas de monitoramento de infraestrutura realizam verificações de ping periódicas para cada ativo, registram o histórico de RTT e perda de pacotes, geram alertas quando a latência ultrapassa os limites definidos e constroem gráficos de tendência que revelam degradações graduais antes que se tornem incidentes.
O ping monitorado continuamente responde perguntas que o ping manual não consegue: a latência para o gateway está aumentando progressivamente ao longo do dia? O link WAN principal tem perda de pacotes esporádica fora do horário comercial? Essas informações alimentam o diagnóstico de causa raiz de incidentes intermitentes que são impossíveis de reproduzir sob demanda.

Conclusão
O ping é a ferramenta de diagnóstico mais simples e mais indispensável em redes IP. RTT, TTL, perda de pacotes e jitter — cada campo da saída carrega informação operacional relevante para diagnóstico de conectividade, estimativa de topologia e avaliação de qualidade de link.
Entender os limites do ping é igualmente importante: ICMP bloqueado não significa host inacessível, e ping manual não substitui monitoramento contínuo automatizado. Em ambientes corporativos, o ping é o sensor base de disponibilidade que, combinado com verificação de porta TCP e monitoramento de aplicações, forma a camada de monitoramento em tempo real que garante visibilidade completa da infraestrutura.
A OpServices implementa monitoramento contínuo com verificação de ping, latência, perda de pacotes e alertas proativos para infraestruturas corporativas. Para estruturar o monitoramento da sua rede, fale com nossos especialistas.
Perguntas Frequentes
O que é ping em redes de computadores?
Echo Request a um endereço IP e medir o tempo de resposta (Echo Reply). O RTT (Round Trip Time) resultante indica a latência entre dois pontos da rede. Além da latência, o ping fornece informações sobre TTL, perda de pacotes e jitter.
O que significa o TTL na saída do ping?
Qual a diferença entre ping e latência?
Por que o ping falha mas o host está online?
Test-NetConnection -Port 443 -ComputerName endereço; no Linux, nc -zv endereço 443.