
Monitoramento de Kubernetes: Guia completo com exemplos

Rodar workloads em Kubernetes mudou a forma como times de operação enxergam disponibilidade. Pods nascem, morrem e migram entre nodes em segundos, e o ferramental tradicional de monitoramento de servidores não acompanha esse ritmo.
Por isso, o monitoramento de Kubernetes deixou de ser um adicional do projeto e virou uma camada obrigatória do dia a dia de SREs, DevOps e equipes de plataforma. Sem ele, fica praticamente impossível garantir SLAs, controlar custo de cluster e identificar a causa raiz de incidentes em ambientes de microsserviços.
Este guia consolida o que importa para monitorar Kubernetes em produção: o que medir, qual pilha montar, exemplos visuais reais com prints de dashboards, principais desafios e boas práticas. Ao final, você encontra um bloco de perguntas frequentes para revisar os pontos mais comuns.
O que é monitoramento de Kubernetes
Monitoramento de Kubernetes é o processo contínuo de coletar, armazenar e analisar métricas, logs, traces e eventos gerados por todas as camadas de um cluster. O escopo cobre o plano de controle (API server, scheduler, etcd, controller-manager), os nodes, os pods, os containers e as aplicações que rodam dentro deles.
Em outras palavras, monitorar Kubernetes não é a mesma coisa que monitorar uma aplicação ou um servidor isoladamente. A prática exige observar simultaneamente a infraestrutura, a orquestração e o workload, porque um problema raramente fica restrito a uma única camada.
Para uma leitura conceitual sobre a plataforma em si, consulte o guia o que é Kubernetes e como ele organiza pods, deployments e nodes. Esta página foca exclusivamente na camada de observabilidade.
Por que monitorar Kubernetes é diferente
Kubernetes introduz três características que tornam a monitoração mais difícil do que a tradicional. Em primeiro lugar, pods são efêmeros: somem sem aviso e reaparecem em outro node, o que invalida o modelo de host fixo. Além disso, a escala é dinâmica, com autoscaling horizontal subindo réplicas a partir de métricas em tempo real.
Por outro lado, a topologia é constantemente reconfigurada pelo scheduler. Um service hoje atende dez pods e amanhã trinta, sem nenhuma mudança de IP ou DNS na perspectiva do consumidor.
Como resultado, a stack de monitoramento precisa fazer descoberta automática de alvos, lidar com alta cardinalidade de labels e correlacionar eventos do Kubernetes (Pod scheduled, OOMKilled, ImagePullBackOff) com métricas e logs.
Os três níveis de observação
Monitorar Kubernetes envolve, simultaneamente, três níveis. No nível de cluster, o foco é capacidade total, saúde do control plane e elegibilidade de nodes. No nível de workload, ficam os deployments, pods, restarts e probes. Por fim, no nível de aplicação, entram latência, taxa de erro e throughput dos serviços que rodam dentro dos containers.
O que monitorar: métricas, logs, traces e eventos
A teoria de observabilidade aplicada a Kubernetes combina os 4 sinais de ouro do SRE (latência, tráfego, erros e saturação) com os métodos USE (Utilization, Saturation, Errors) para recursos e RED (Rate, Errors, Duration) para serviços.
A tabela abaixo resume os principais sinais por camada, como capturá-los e por que cada um importa em produção.
| Sinal | Como coletar | Por que importa |
|---|---|---|
| Saúde do control plane | Métricas do API server, kube-apiserver, scheduler e etcd |
Sem control plane saudável, scheduling e rollouts param |
| Recursos de node | CPU, memória, disco e rede via node-exporter e cAdvisor |
Saturação de node causa eviction e degradação em cascata |
| Estado de objetos | Deployments, replicasets e pods via kube-state-metrics |
Mostra divergência entre estado desejado e real |
| Eventos do cluster | Stream do kubectl get events exportado para o backend |
Sinaliza OOMKilled, ImagePullBackOff e crash loops |
| Logs de aplicação | Agregação via Fluent Bit, Vector ou Loki em formato estruturado | Diagnóstico fino quando a métrica só mostra o sintoma |
| Traces distribuídos | Instrumentação com OpenTelemetry exportando para Tempo, Jaeger ou backend SaaS | Conecta requisições entre serviços e revela gargalos |
Vale destacar que essas quatro fontes (métricas, logs, traces e eventos) não são intercambiáveis. Cada uma responde a um tipo diferente de pergunta operacional, e a maturidade do monitoramento aparece justamente em como o time correlaciona os sinais.
Pilha típica de observabilidade para Kubernetes
Existem três caminhos principais para montar a pilha de observabilidade de um cluster. O primeiro é a stack open-source baseada em Prometheus, Grafana e Alertmanager. O segundo é uma plataforma SaaS comercial. O terceiro são os serviços nativos do provedor cloud (CloudWatch Container Insights, Azure Monitor, Google Cloud Operations).
Cada opção tem vantagens e limitações claras. A comparação abaixo ajuda na decisão.
| Dimensão | Open-source (Prometheus stack) | SaaS comercial | Cloud nativo |
|---|---|---|---|
| Custo inicial | Sem licença | Por host ou ingestão | Por GB e por métrica |
| Esforço operacional | Alto: gestão da própria pilha | Baixo: agente plug and play | Médio: integrado ao IAM do provedor |
| Retenção longa | Requer Thanos, Cortex ou Mimir | Nativa | Nativa, com custo proporcional |
| Portabilidade | Padrão CNCF, aberta | Vendor lock-in moderado | Lock-in alto no provedor |
| Componentes típicos | kube-prometheus-stack |
agente proprietário |
container insights |
A maioria das equipes maduras combina as três abordagens. Por exemplo, Prometheus para métricas de plataforma, uma SaaS para APM e RUM, e o serviço nativo da nuvem para faturamento e governança. O importante é evitar duplicidade total, que multiplica custo sem agregar visibilidade.
5 benefícios do monitoramento Kubernetes
Independentemente da pilha escolhida, o monitoramento de Kubernetes traz cinco benefícios diretos para o time de operações.
1 — Detecção de erros e alertas em tempo real
Com métricas e eventos correlacionados, problemas como pods em CrashLoopBackOff, falhas de readiness probe ou saturação de node aparecem em segundos. Como resultado, o time atua antes que o usuário final perceba degradação.
2 — Gerenciamento e otimização de carga
A coleta contínua de uso de CPU e memória alimenta o Horizontal Pod Autoscaler e o Vertical Pod Autoscaler. Dessa forma, o cluster escala de modo previsível, sem provisionamento manual e sem desperdício de recurso reservado.
3 — Descoberta de causa raiz
Ao cruzar métricas, logs, traces e eventos, o tempo médio de diagnóstico cai drasticamente. Um pod que reinicia repetidamente, por exemplo, fica explicado pela combinação de OOMKilled no evento, pico de memória na métrica e exceção específica no log.
4 — Visibilidade de custos
Métricas de uso por namespace, deployment e label permitem alocar custo de cluster por equipe ou produto. Por isso, monitoramento maduro é pré-requisito para qualquer iniciativa de FinOps em ambientes Kubernetes.
5 — Insights operacionais
Dashboards históricos revelam padrões sazonais, regressões em deploy e dependências escondidas entre serviços. Esses insights orientam decisões de capacidade, refatoração e priorização do roadmap de plataforma.
Exemplos de monitoramento Kubernetes
A teoria fica mais clara com exemplos visuais. Os dois prints abaixo mostram dashboards reais utilizados em ambientes de produção monitorados pela OpServices.
O primeiro exemplo apresenta uma visão centralizada de métricas de containers e microsserviços. O dashboard reúne consumo de memória, uso de CPU, banda por segundo e informações de nodes e pods em uma única tela, o que acelera a triagem de incidentes pelo time de operação.
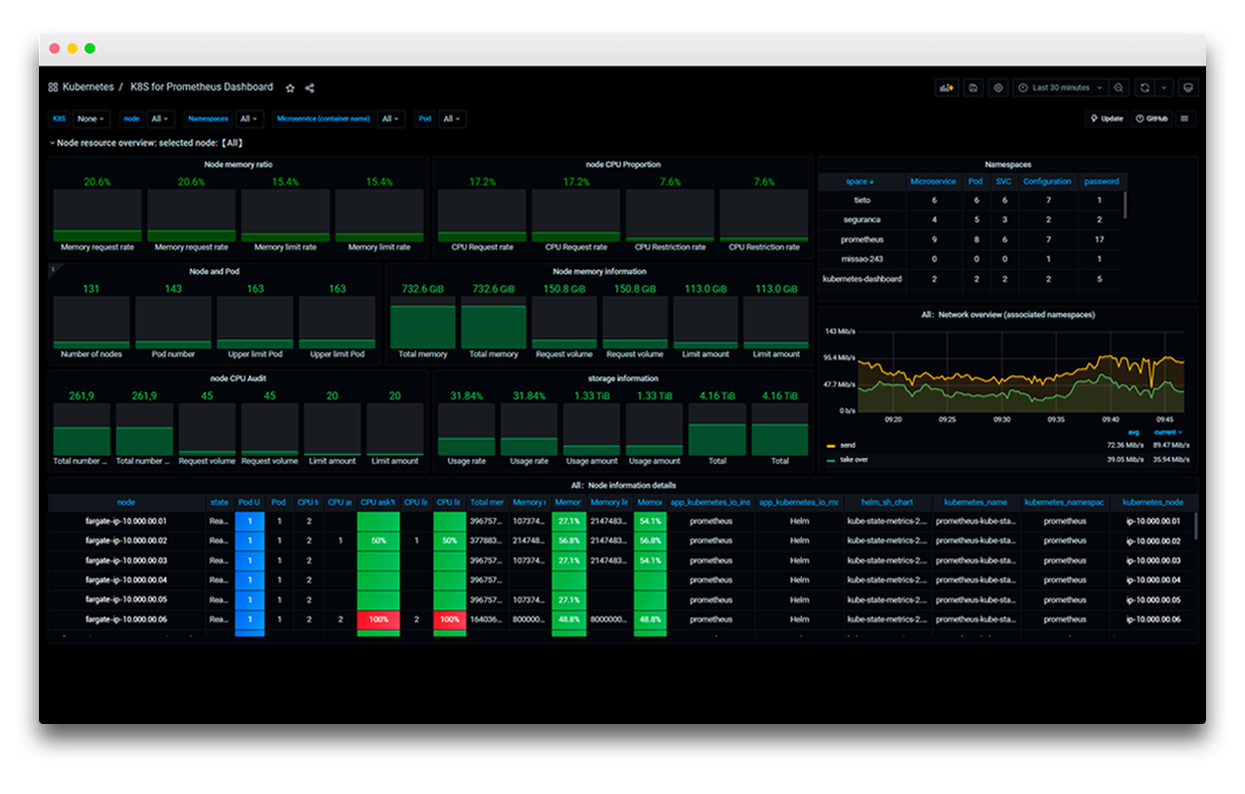
Em seguida, o segundo dashboard detalha a camada de nodes e pods. A visualização lista cada node com seu respectivo estado e expõe métricas de CPU, memória e disco em granularidade individual, o que ajuda a identificar rapidamente o componente saturado em um cluster grande.
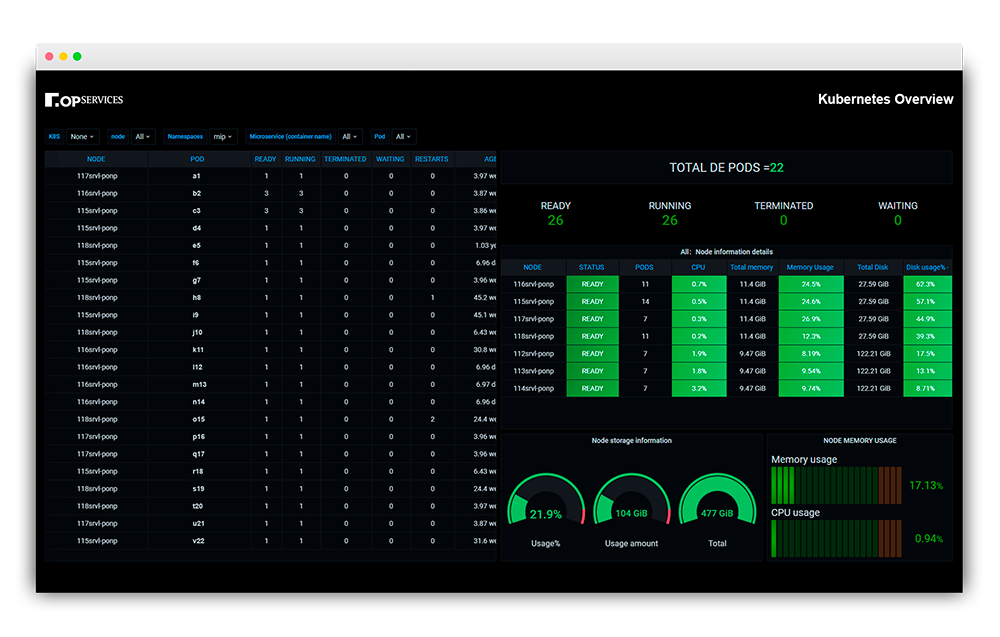
Os dois exemplos seguem o mesmo princípio: dashboards organizados por camada (cluster → node → pod → container) e linkados entre si para que a navegação acompanhe o fluxo natural da investigação.
Principais desafios de monitorar Kubernetes em produção
Mesmo com a pilha certa, alguns desafios aparecem em todo cluster que cresce. Os mais comuns são quatro.
O primeiro é a cardinalidade alta. Cada combinação única de labels gera uma série temporal, e em clusters com centenas de pods o custo de armazenamento explode rapidamente. Por isso, vale aplicar relabeling agressivo para descartar labels sem valor operacional, como pod_template_hash.
O segundo é o custo de logs. Em ambientes com milhares de réplicas, a ingestão de logs supera com facilidade o orçamento de observabilidade. Soluções como Loki ajudam por indexar apenas labels, e não o conteúdo completo. Ainda assim, é necessário definir políticas de retenção por severidade.
O terceiro desafio é o ruído de alertas. Pods reiniciam por design em rolling updates, e alertas mal calibrados disparam o tempo inteiro. A melhor prática é alertar com base em sintomas voltados ao usuário (latência fora do SLO, taxa de erro acima do budget), e não em causas técnicas isoladas.
Por fim, o storage efêmero de pods exige que logs e métricas saiam do node antes do término do container. Caso contrário, dados de diagnóstico se perdem no momento exato em que são mais necessários.
Boas práticas para monitoramento Kubernetes em produção
Quatro boas práticas separam um monitoramento que apenas registra de um monitoramento que sustenta a operação. Antes de tudo, defina SLOs por serviço, e não por componente de infraestrutura. O SLO traduz expectativa de negócio em métrica observável e orienta priorização de incidentes.
Em segundo lugar, organize dashboards por camada. Cluster, namespace, deployment, pod e container devem ter painéis dedicados, conectados por links contextuais. Vale dizer que dashboards monolíticos só funcionam em clusters pequenos.
Outro ponto é usar autoscaling baseado em métricas reais, e não em valores arbitrários de CPU. Métricas de latência, fila de mensagens ou requisições por segundo refletem melhor a demanda do serviço.
Por último, trate a configuração de observabilidade como código. Manifests de ServiceMonitor, regras de alerta e dashboards do Grafana devem viver no repositório junto com a aplicação, idealmente sob GitOps. Esse princípio se conecta diretamente aos conceitos descritos no guia o que é observabilidade e em soluções de observabilidade em escala corporativa.
Para aprofundamento técnico, a documentação oficial do projeto e a lista de projetos graduados pela CNCF são referências constantemente atualizadas pela comunidade. Vale também consultar a capítulo do livro de SRE do Google sobre sistemas distribuídos.
Visibilidade completa de pods, nodes e clusters Kubernetes em produção.
Monitoramos health checks, consumo de recursos e eventos de orquestração para equipes que rodam workloads críticos em containers.
Conclusão
Monitorar Kubernetes exige uma abordagem diferente do monitoramento tradicional de servidores. O ambiente é dinâmico, com pods efêmeros, escala automática e topologia em constante mudança, o que demanda coleta automática, alta cardinalidade controlada e correlação entre métricas, logs, traces e eventos.
Em resumo, uma operação madura combina os sinais certos, a pilha adequada (open-source, SaaS ou cloud nativo), dashboards organizados por camada, alertas baseados em SLO e disciplina para tratar a observabilidade como código. Quando esses pilares estão no lugar, o cluster deixa de ser uma caixa preta e passa a sustentar SLAs reais.
Para acelerar essa jornada com apoio especializado, fale com um especialista da OpServices e descubra como elevar a maturidade do monitoramento do seu ambiente Kubernetes.
Perguntas Frequentes
O que é monitoramento de Kubernetes?
Quais métricas monitorar em Kubernetes?
API server e do etcd. No node, CPU, memória, disco e rede via node-exporter e cAdvisor. No workload, estado de deployments e pods via kube-state-metrics, com restarts e probes. Na aplicação, latência, taxa de erro e throughput (sinais de ouro do SRE). Eventos do cluster como OOMKilled e ImagePullBackOff completam o quadro e devem ser exportados para o mesmo backend.Prometheus e Grafana são suficientes para monitorar Kubernetes?
kube-state-metrics, node-exporter e Alertmanager via Helm chart kube-prometheus-stack. Para retenção longa, é necessário adicionar Thanos, Cortex ou Mimir. Para logs e traces, a pilha precisa crescer com Loki ou Elasticsearch para logs e Tempo ou Jaeger para traces. Em clusters muito grandes ou com requisitos de APM avançado, plataformas SaaS comerciais costumam complementar ou substituir parte da stack open-source.Quais são os principais desafios de monitorar Kubernetes em produção?
Como funciona o kube-state-metrics?
kube-state-metrics é um serviço que escuta a API do Kubernetes e expõe, em formato Prometheus, métricas sobre o estado dos objetos do cluster: deployments, replicasets, pods, jobs, statefulsets e demais recursos. Ele não mede consumo de recurso (isso fica com node-exporter e cAdvisor) e sim divergência entre estado desejado e estado real. Por exemplo, sinaliza pods em Pending, deployments com réplicas indisponíveis ou jobs falhos, dados essenciais para alertas de saúde do workload.
